Create Land Cover Maps Like a Pro: Using Sentinel-2 and Machine Learning
Posted on May 5, 2024 • 17 min read • 3,501 wordsLand cover classification using Sentinel-2 imagery and applying supervised minimum distance algorithm and machine learning approaches

Land cover classification using Sentinel-2 imagery and applying supervised minimum distance algorithm and machine learning approaches
Introduction
Land use/land cover (LULC) maps serve to assess the effect of human’s impact on natural resources. The accurate/updated maps establish the baseline information in effective planning, management and monitoring programmes at local, regional and national levels. Furthermore, the accurate/updated maps are the clue to better comprehension of land utilization aspects and also they are a key factor in the adjustment of policies and measurements required for further development planning. Also, sustainable development requires to monitor current processes on LULC patterns over the time. LULC maps are essential in order to observe and monitor the ecosystem. Thus, it is an important input in order to make policies and launch programmes to govern in a sustainable way and help to save the environment for future generations (Satpalda,2002). Remote sensing (RS) has become one of the most effective tools to capture data for map creation. The main advantages of remote sensing is that it covers a large area (reduces time in data capture on field surveying significantly), provides an overview of certain spatial patterns and also shows the temporal changes. (Eklundh,2020)
The aim of this study was to create accurate and reliable land cover maps of Lund Municipality based on Sentinel-2 satellite imagery conducting four supervised classification approaches using predefined classes: Minimum Distance, Support Vector Machine(Cortes and Vapnik, 1995), Artificial Neural Networks and Random Forest (Breiman, 2001). Such classification production requires preprocessing steps such as geometric correction, image analysis.
Study area and data
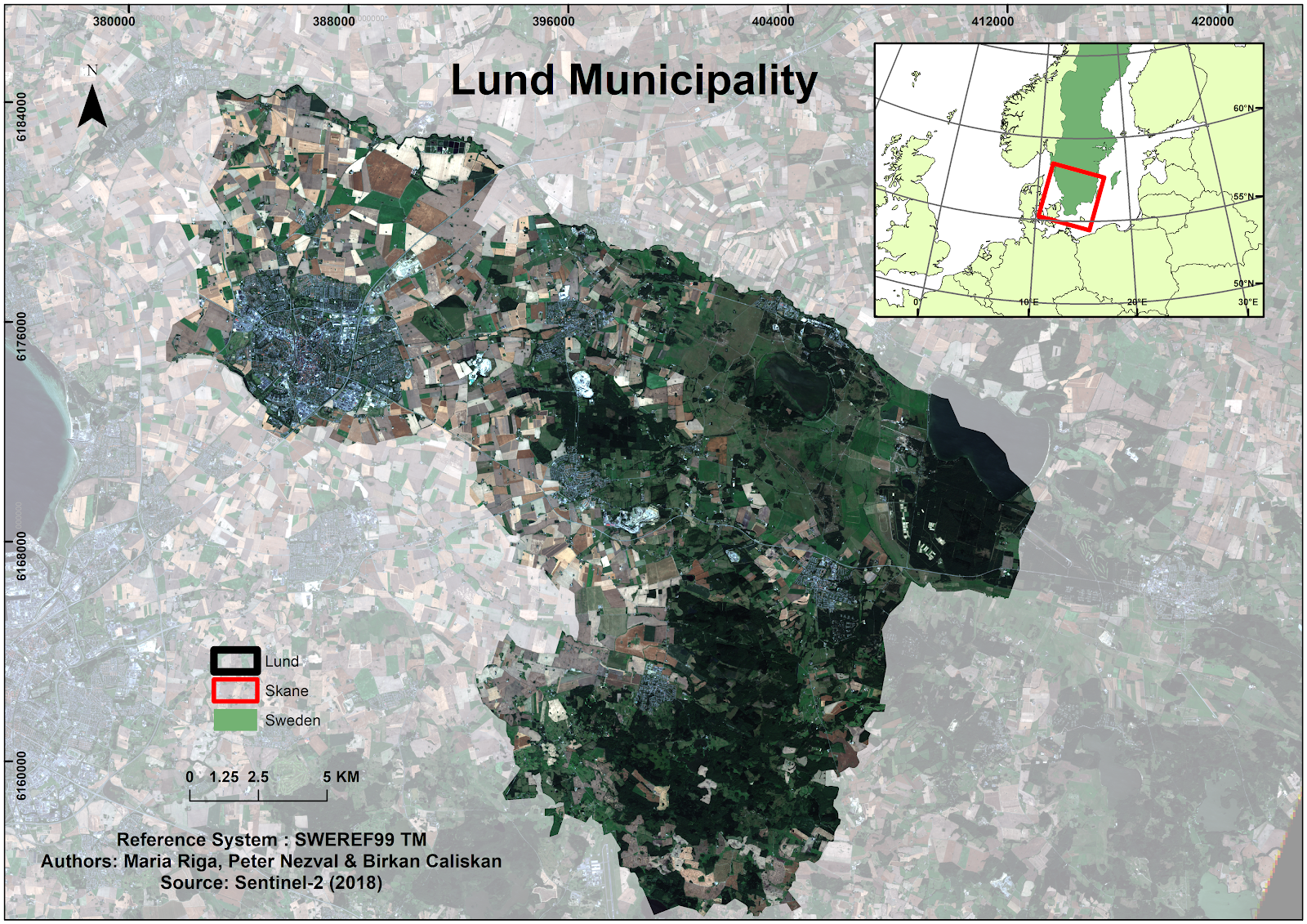
Figure 1. Study area.
The study area concerns Lund municipality in Scania, Sweden.The municipality of Lund is located approximately between coordinates 380000 and 414000 (E-W) and 6153000 and 6185000 (S-N), therefore, it comprises the 1018.65 km2area of Lund kommun and its neighbouring area. The study area consists of built-up areas, agriculture zones, water bodies and infrastructure buildings such as roads, rail tracks and an airport. The Spot 5 image was taken on June 10, 2011. It has 10m by 10m pixel resolution and consists of four bands which are the following:
Band 1 : Green
Band 2: Red
Band 3: Near Infrared (NIR)
Band 4: Mid Infrared (MIR)
Lantmäteriets topographic raster map was used as a reference image and specifically the near infrared (NIR) band.
Additionally, the Sentinel-2 satellite imagery data includes 13 wavelength bands and were reprojected to Swedish geodetic reference system SWEREF99 and resampled to 10m spatial resolution, so no further transformations or re-projections were needed. The band images had the processing level 1C, which means that radiometric and geometric correction had already been performed. The data are consisted of 3 satellite imagery (Appendix A, table A1):
Sentinel-2 (10 m spatial resolution) - 4 bands
Sentinel-2 (20 m spatial resolution) - 6 bands
Sentinel-2 (60 m spatial resolution) - 3 bands
Methodology
Data pre-processing
Geometric correction
The first essential step was to perform the geometric correction and georeferencing. Geometric correction is the process of correcting the geometric distortion. These distortions occur due to variations in different positions caused by Earth rotation or Earth flattening.
Cropped topographical raster was used as the reference input image for the georeferencing. Georeference is the transformation of geographic data into a known coordinate system so it can be viewed and analyzed with other geographical data. Another mapping application was used in order to find suitable locations inside and past the edges of Lund municipality. As can be seen (Appendix B, figure B1), 16 ground control points (GCPs) were chosen in order to perform this task.
Image enhancement and spectral properties
Image enhancement is a method that is usually used in order to improve the visualization of objects and features in the satellite imagery. There is a lower user’s ability to identify objects, features, land-use classes, patterns or any other information necessary for the spatial analysis without image enhancement. However, image enhancement is only a mean to improve the visual interpretation and understanding of images. Radiometric values remain unchanged but easier to recognize content in the image for an user.
Satellite imagery used in this project has been enhanced in the contrast domain and the spectral domain. Firstly, outliers have been removed by cumulative count cut. The values for the cut were 2% of the lowest values as well as 2% of the highest values. These values always can vary for different images. It is important to find a compromise between improving the perception of the image and removing values because it can cause a loss of information. Another step was to correct the brightness and luminance by changing the value of gamma correction.
Improved visualization of satellite images allowed to commence a visual investigation and an identification. However, different land classes/covers and surfaces have different properties for emitting, transmitting or reflecting the radiation flux. In order to utilize the entire possible spectrum that particular bands cover, raster images were split to single bands followed by stacking them into one raster file. Having all the bands in one file provides an opportunity to create satellite composite pictures, calculate correlation between separate bands or use those bands for creating a signature file through entire spectral bands.
Field survey data collection
Training and validation data collected by the students from last year were evaluated and assessed through high resolution satellite imagery on google earth pro as well as with field trip. Our group, 2D, decided to sample points by stratified method over our area (Appendix B, figure B2) through google earth software, while the group 1B applied a simple random method. 300 points were sampled and saved to their corresponding one of the eight land cover classes. These land cover classes are: water (1): lakes, rivers; broadleaf (2): broadleaved wood stemmed vegetation; needleleaf (3): needle leaved wood stemmed vegetation; agriculture (4): cultivated fields; other vegetation (5): vegetation other than wood stemmed or agriculture, e.g pasture, urban green grass areas etc.; paved surface (6): asphalt roads, parking lots; building (7): any type of roof on building; Other earth material (8): Surfaces that are stone/gravel/cobblestone/bare soil, but not paved. Subsequently, all the points from groups were merged and shared for further analysis.
Supervised classification
Supervised classification is the technique most often used for the quantitative analysis of remote sensing image data. The user specifies the various pixels values or spectral signatures that should be associated with each class. This is done by selecting representative sample sites of a known cover type called Training Sites or Areas. The computer algorithm then uses the spectral signatures from these training areas to classify the whole image. (GSP216, Introduction to Remote Sensing)
Minimum Distance Method
Minimum distance classification method basically assigns each unknown pixel to the closest class center (mean value) using the euclidean formula. The mean values are calculated from training sites. In this study, supervised classification using the minimal distance method algorithm was carried out in 2 software environments - IDRISI TerrSet and QGIS. Both classification approaches followed the same process:
dividing sampling points randomly (70% for training and 30% for evaluation purposes)
creating training site and signature files
classification
evaluation
Machine Learning Approaches
For machine learning classification, three algorithms: support vector machines, random forest and neural network models were conducted. Samples points were divided into 70-30 by class for the training and evaluation purposes. The classification predictions were compared to the evaluation samples.
Results
Geometric correction
After georeferencing to the coordinate system SWEREF99™ and bilinear resampling the result was obtained. The total root mean square error (RMSE) was 0.55. This value indicates a good fit of GCPs to the reference image.
Image enhancement and spectral properties
The visual investigation of the study area started with the true color composition, which looks almost exactly the same as human’s eyes can observe reality. However, taking a look at the histogram (Appendix C, figure C1) indicates that Bands 2 ((Blue) in the figure marked as Band 1), 3 (Green) and 4 cover almost the same pixel values and they are highly correlated, especially Blue and Green bands. The fact mentioned before can cause a deep water with a low reflectance value can be changed for a needleleaf vegetation, which has also a low reflectance value and seems very dark. It means that other spectral bands are very important to use in order to figure out correct features in the images.
The false color composition emphasizes the vegetation cover. It happens because of the NIR band (Band 8) and its ability to detect chlorophyll (green pigment) in plants. Composite combining band 11,8 and 2 is appropriate a way to observe healthy crops and agriculture lands. To distinguish well bare soil the SWI composite bringing together bands 12, 8A and B4 was utilized. Furthermore, NDVI index was calculated. NDVI index presents the information about the volume of vegetation. High values (~1) indicate vegetation land cover as long as low values (~0 or 0 > i) mean urban areas, respectively areas without vegetation. All composites created and used in land classes identification can be seen in the figure 1.
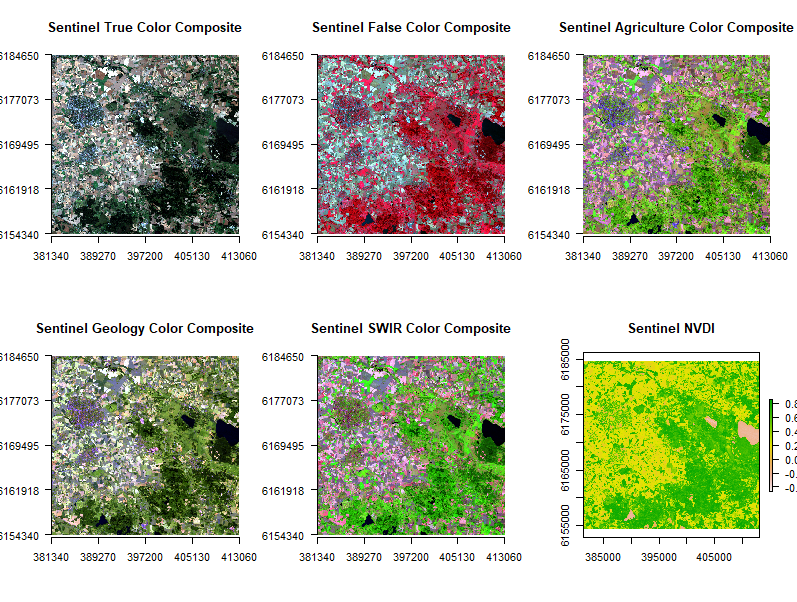
Figure 2 . Composites using different bands
After enhancing the imagery, analyzing the values and correlation and creating composites it was possible to identify 8 land use/land cover classes:
Water
Broadleaf vegetation
Needleleaf vegetation
Agriculture
Other vegetation type (e.g. grassland)
Paved roads
Buildings
Other Earth Material

Figure 3 .Spectral properties of land use/land cover classes included range of values
Figure 3. shows how pixel values for each class change in relationship with wavelength (bands). Within longer wavelength values for classes are very similar except urban areas (buildings). This value is basically consistent through all spectrums. Values smoothly decrease in the range of visible light (b2-b4), only one exception is b2(blue), which has decreasing tendency through the entire part of spectrum used. After leaving a range of visible light all the other bands quickly increase until reaching the peak in the wavelength that corresponds to b8(NIR). With decreasing wavelength, also a slow decrease of pixel values can be observed. This only highlights the importance of using different spectral bands to correct interpretation of satellite images.
Supervised classification - Minimum distance and machine learning approaches
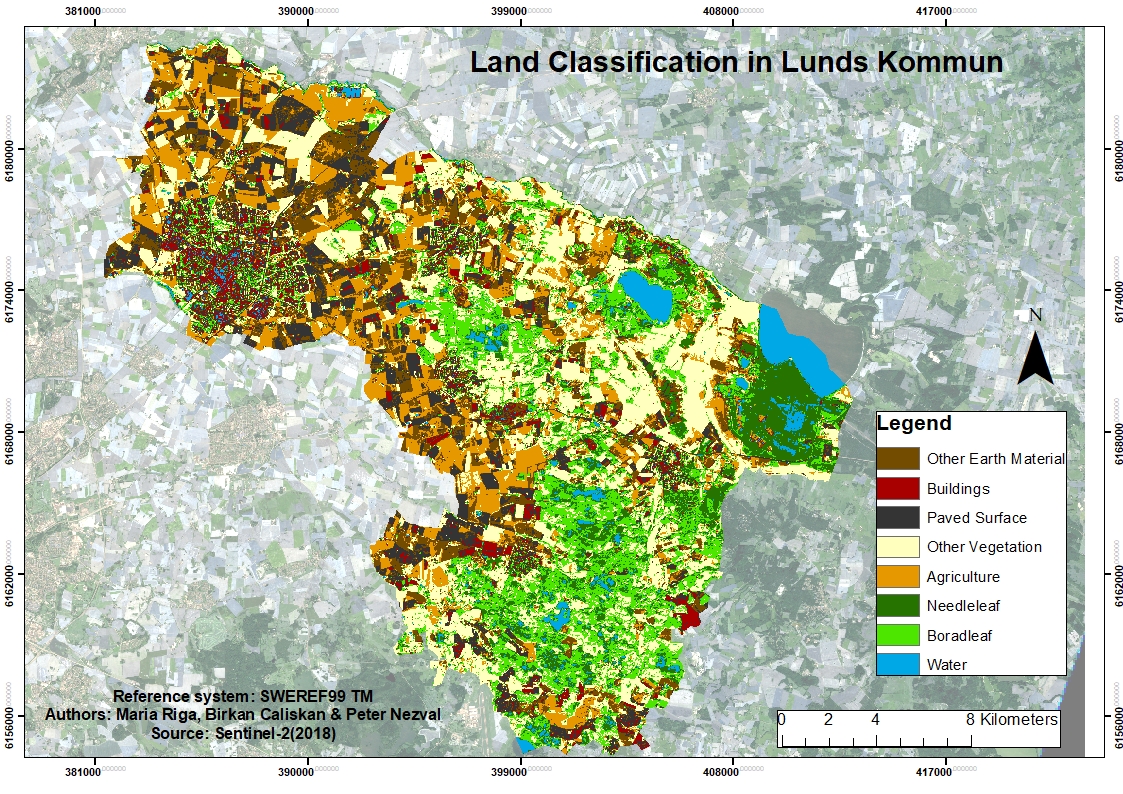
Figure 4 . Land classification using minimal distance method in Lunds Kommun performed in TerrSet

Figure 5 . Land classification using minimal distance method in Lunds Kommun performed in QGIS

Figure 6. Machine learning classified maps by three models: support vector machines model (a), random forest model (b), neural network model(c).

Figure 7. Percentage of final classes derived by three machine learning model. SVM = Support Vector Machines, RF = Random Forest, NNET = Neural network, MN = Minimum Distance.
The total area of Lund municipality is equal to 178510 cells, which is equal to 1785.1 km2. The most occurring class for each of the model is dissimilar. NNET model classifies the area mostly by broadleaf class (29.41 %), while RF model mostly classifies the area by agriculture class. On the other hand, the most dominant class for SVM model is other vegetation type. The total area of the most dominant class for each of the model are 524km2, 534km2 and 496 , respectively( Appendix D, table D1.). The classes derived by minimum distance method are nearly uniformly distributed over the area. The most dominant class computed by Terrset and Qgis, appears to be other vegetation type with 20.18 % and 26.71%, respectively.

Figure 8. Final classified maps comparison in detail over Krankesjön lake. True color composite-A, neural network-B, support vector machine-C, minimum distance-D, random forest-E.
Accuracy assessment


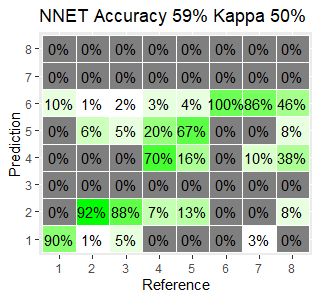
Figure 9. Normalized cross-tabulation of observed and predicted classes for each of the classifiers, where the classes are numbered with unique IDs, 1=Water, 2=Broadleaf, 3= Needleleaf, 4= Agriculture, 5= Other vegetation, 6= Paved Surface, 7= Building 8= Other Earth Material. The diagonal axis shows the degree of correct prediction.
Kappa reflects the difference between prediction and reference values. The confusion matrix is normalized for each class and therefore the percentage of the accuracy for each class can be assessed. Among all the machine learning classification models, the most accurate model appears to be RF with the largest kappa (87%), whereas NNET model is the least one with 50% kappa percentage. SVM model is validated with moderate kappa percentage, 63%. Cross- tabulation for nnet model shows the great conflict between prediction and reference values in some classes. The classes needle leaf, buildings and other earth material, for instance, are never predicted by the model. The misclassification occurred in the nnet model, 88% of the broad-leaved object classified as needle-leaved objects as well as 86% of building class classified as paved surface. Likewise, the similar classification confusion between needle leaf and broadleaf pixels appears in the models SVM and RF with 61% and 22% misclassification percentage.
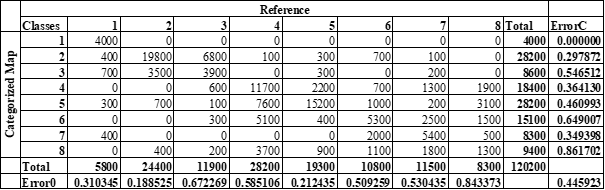
Table 1. Confusion matrix of minimum distance method in TerrSet with user accuracy and producer accuracy for each classes, 1=Water, 2=Broadleaf, 3= Needleleaf, 4= Agriculture, 5= Other vegetation, 6= Paved Surface, 7= Building 8= Other Earth Material
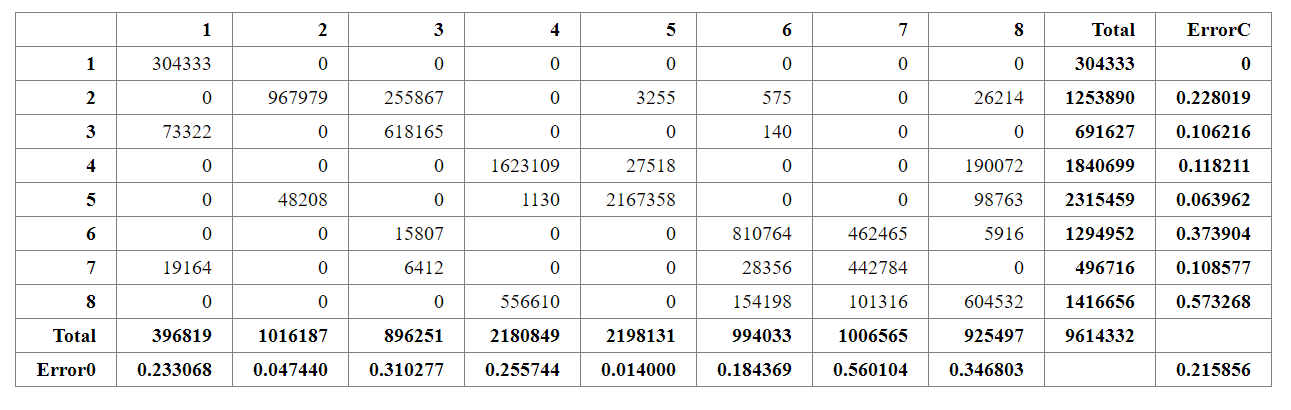
The table above shows the confusion matrix of minimum distance method and user and producer accuracy for each of the class. Similar table is provided also for the minimum distance method performed in QGIS as Figure D2 (Appendix D). Overall kappa is equal to 0.74, which means, in comparison to machine learning algorithms it has relatively larger kappa than NNET and SVM. Overall kappa index for the same task carried out in QGIS was 0.47. This value is very close to the value of the NNET method. Similar misclassification errors can be observed from the confusion matrix above such as incorrect classification between broadleaf and needleleaf classes as well as misclassification between paved surface and buildings.
Clouds and cloud shadows may lead to misclassification. Any clouds and their shadow were not inspected in our study area. There are several models to eliminate severe atmospheric distortions, such as FMASK(Zhe Zhu and Woodcock 2012) and sen2cor.Fmask, for instance, exploits the high reflectance value of dense clouds in the blue and SWIR bands. Likewise, over the area where cirrus clouds appear, due to high reflectance in the B10 band and low reflectance in the B2 band, this form of clouds can be identified. The sentinel-2 L1C products come with cloud vector mask embed.
Discussion
There are apparent inconsistencies within produced map outputs and accuracy assessment in this project. This could be caused by several sources of errors. They can be categorized as following:
defining incorrect LULC classes caused by inappropriate image enhancement
errors in the sampling data and devices used for data capture + user’s error given in respect to a lack of experience
software differences and limitations
Classes in the study area have been classified relatively well but there are still quandaries about several classes. For example, all crop-field types are classified as “agriculture class” even though they have very different pixel values. It is hard to uniformly classify such a heterogeneous class. The range of pixel values can be seen also in the Figure 3. Moreover, the class including buildings can be hard to classify as well. Roofs of buildings are made from different materials (roof tiles, metal or green-roofs) with different spectral properties. This can lead to misclassification.
Time can be one of the most important error sources in the sampling process. There are 2 main reasons that can explain errors:
time difference between capturing the satellite image and field sampling
seasonal difference (different phenological period)
Satellite images used were captured in 2015 and actual field sampling was carried out in 2019. Also, the interval between the sentinel-2 satellite imagery acquired in August and the field sampling period in April may negatively influence the human classification decision, specifically, decision between agriculture and other earth materials. During sampling period, agriculture areas consisting of un-flourished vegetations are likely to appear as bare soils to human-eye, which is causing the incorrect class definition. Similarly, due to the low sensitivity in green color to human-eye, class definition for needleleaf and broadleaf vegetations through high-resolution satellite imagery may produce mistrained data. Besides using google earth pro, which only shows true color composite, other band combinations could take into account to rule out human error. Furthermore, the fact that the rather mediocre precision of GPS observations acquired by mobile phones, observations recorded at where two classes adjacent might be registered incorrectly. Such positioning impreciseness could be more problematic in urban areas and under tree cover. Devices attached high-sensitivity GPS receiver, and coordinate measurements conducted distant from adjacent classes could overcome this error.
Training processes are limited to 100 iterations, the higher training iterations to the machine may increase the accuracy, which could also increase the process time. Therefore, tailor-fit decisions to balance between computing time and accuracy should be considered. Moreover, the training methodology for machine learning approaches is based on four input bands although sentinel-2 consists 13 bands to be considered for training, as well as NDVI band combination may help to distinguish vegetation types since there are three vegetation types aimed to be classified in the study area. There were also several software differences while using GIS software (IDRISI, QGIS), especially in the process of creating signature files. QGIS provides an user interface with more options to control the process (e.g. setting up thresholds for minimal distance) while IDRISI works more or less as a black box with a low control of the process by the user.
Even though random forest resulted with the largest kappa, it can be seen that the noisy classification occured over the study area. For overall eyeballing, classification errors presented in figure 8 for Krankesjön Lake. Needleleaf, for example , was not classified in this specific area by artificial neural networks, and in the middle of the lake some cells are defined with paved surfaces. Similar pattern within the lake was occured for the random forest. Also, there are innumerable sliver polygons over the area. Minimum distance, on the other hand, roughly obtains the correct pattern, however, some needleleaf areas were classified as water . In conclusion, the comparison above demonstrates that SVM classifies the area more correctly than other methods.
Conclusion
The aim of creating a land cover classification map for Lund municipality was achieved. Totally 5 map outputs were produced using three machine learning algorithms and minimum distance method conducted in 2 different software environments. Despite getting relatively high overall accuracy for certain methods (RF - 89%) it is still questionable if the maps really show the reality. One should keep in mind all the limitations and especially the long time interval between satellite imagery acquisition and sampling data capture. From the results obtained, both statistics and actual maps, it seems that the Support Vector Machine method is the most accurate and appropriate method for creating a LULC map in this study area.
References
Breiman, L., 2001. Random forests. Machine learning, 45(1), pp.5-32.
Cortes, C. and Vapnik, V., 1995. Support vector machine. Machine learning, 20(3), pp.273-297.
Zhe Zhu, Curtis E.Woodcock. 2012. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sensing of Environment, 118: 83-94. DOI: 10.1016/j.rse.2011.10.028.
GSP216, Introduction to Remote Sensing - http://gsp.humboldt.edu/OLM/Courses/GSP_216_Online/lesson6-1/supervised.html [online]
Satpalda Geospatial Services - https://www.satpalda.com/blogs/significance-of-land-use-land-cover-lulc-maps [online]
Lars Eklundh - NGEN08 Intrdoduction to Remote Sensing 2020 (Lecture slides)
Table A1. Spectral information list
| Band | Characteristics | Resolution(m) | Central(nm) |
|---|---|---|---|
| B01 | Ultra Blue(Coastal and Aerosol) | 60 | 443 |
| B02 | Blue | 10 | 490 |
| B03 | Green | 10 | 560 |
| B04 | Red | 10 | 665 |
| B05 | Vegetation Red Edge | 20 | 705 |
| B06 | Vegetation Red Edge | 20 | 740 |
| B07 | Vegetation Red Edge | 20 | 783 |
| B08 | Near infrared | 10 | 842 |
| B08A | Vegetation Red Edge | 20 | 865 |
| B09 | Water vapour | 60 | 945 |
| B10 | SWIR - Cirrus | 60 | 1375 |
| B11 | SWIR | 20 | 1610 |
| B12 | SWIR | 20 | 2190 |

Figure B1. Depicts the GSP selections
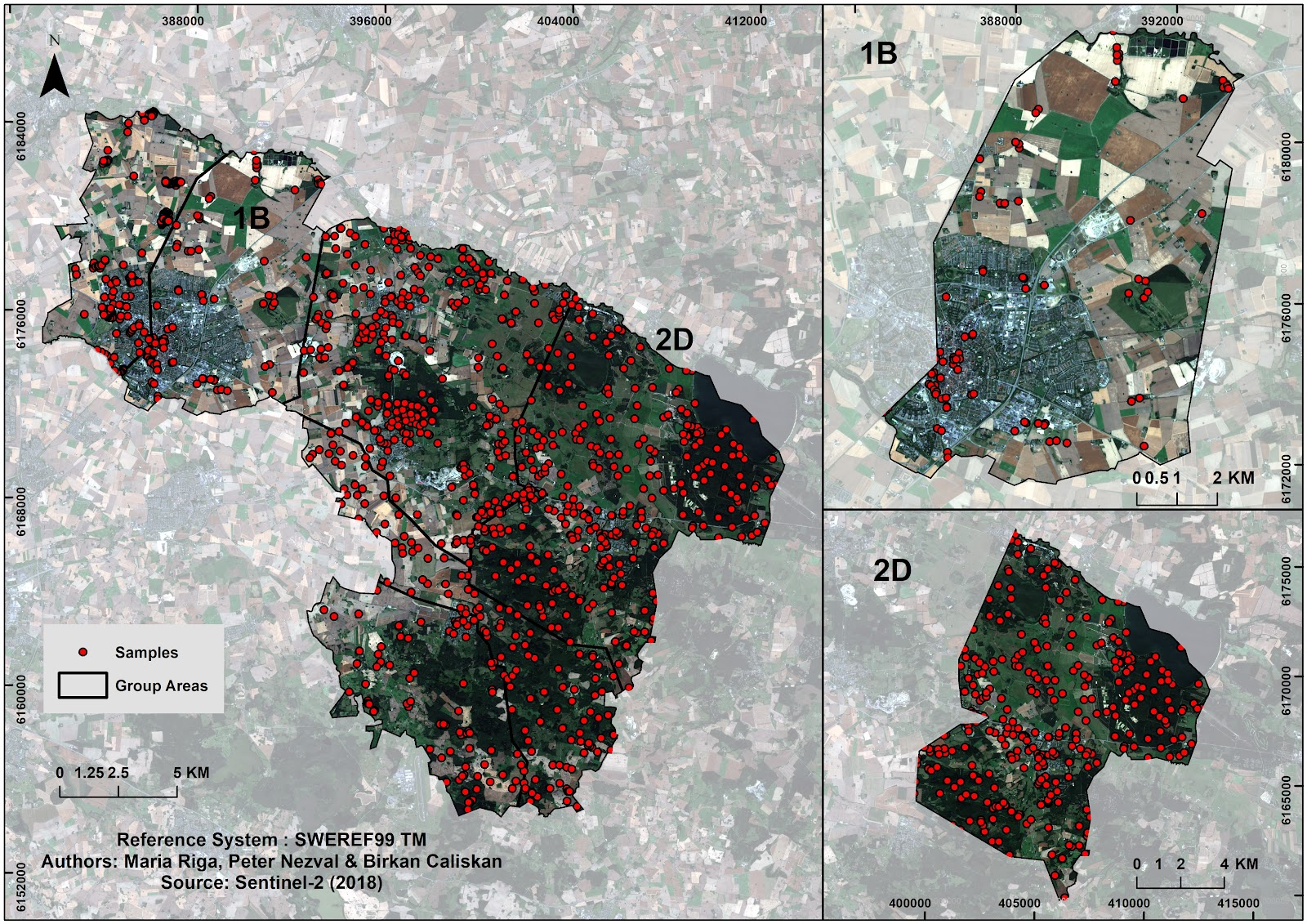
Figure B2. Distribution of samples in Lund Municipality with zoom-in map of the area for group 1B and 2D

Figure C1 - Histogram of pixel values (without bands B1,B9,B10)
Table D1 . Total area and percentage of classes from final classified maps derived by five algorithms.
| SVM[km²] | RF[km²] | NNET[km²] | QGIS[km²] | MinDist [km²] | Mean[km²] | |
|---|---|---|---|---|---|---|
| Water | 17.72 (0.99%) | 20.62 (1.16%) | 38.53 (2.16%) | 7.16 (0.4%) | 42.02 (2.35%) | 25.21 (1.41%) |
| Broadleaf | 370.3 (20.74%) | 324.6 (18.18%) | 524.94 (29.41%) | 343.7 (19.25%) | 299.39 (16.77%) | 372.586 (20.87%) |
| Needleleaf | 118.5 (6.64%) | 117.73 (6.6%) | 1.09 (0.06%) | 126.07 (7.06%) | 195.21 (10.94%) | 111.72 (6.26%) |
| Agriculture | 453.8 (25.42%) | 533.99 (29.91%) | 491.44 (27.53%) | 299.4 (16.77%) | 248.15 (13.9%) | 405.356 (22.71%) |
| Other vegetation | 495.78 (27.77%) | 375.06 (21.01%) | 369.58 (20.7%) | 476.77 (26.71%) | 360.29 (20.18%) | 415.496 (23.28%) |
| Paved surface | 163.02 (9.13%) | 144.15 (8.08%) | 359.06 (20.11%) | 195.03 (10.93%) | 273.1 (15.3%) | 226.872 (12.71%) |
| Building | 137.19 (7.69%) | 171.06 (9.58%) | 0.46 (0.03%) | 125.98 (7.06%) | 140.01 (7.84%) | 114.94 (6.44%) |
| Other earth material | 28.79 (1.61%) | 97.89 (5.48%) | 0 (0%) | 210.99 (11.82%) | 226.93 (12.71%) | 112.92 (6.33%) |
| Total | 1785.1km2 (100%) | 1785.1km2 (100%) | 1785.1 km2(100%) | 1785.1 km2(100%) | 1785.1 km2(100%) | 1785.1km2 (100%) |
Table 2D. Confusion matrix of minimum distance method in QGIS with user accuracy and producer accuracy for each classes, 1=Water, 2=Broadleaf, 3= Needleleaf, 4= Agriculture, 5= Other vegetation, 6= Paved Surface, 7= Building 8= Other Earth Material