Micro-Mobility Case Study - Interactive Dashboard for OD Dataset
Posted on May 9, 2024 (Last modified on September 10, 2024) • 7 min read • 1,283 wordsInteractive Mobility Dashboard for OD Dataset using Geographic Information Systems (GIS)

Micro-Mobility Case Study - Interactive Dashboard for Origin Destionation Dataset (IDOD)
Introduction
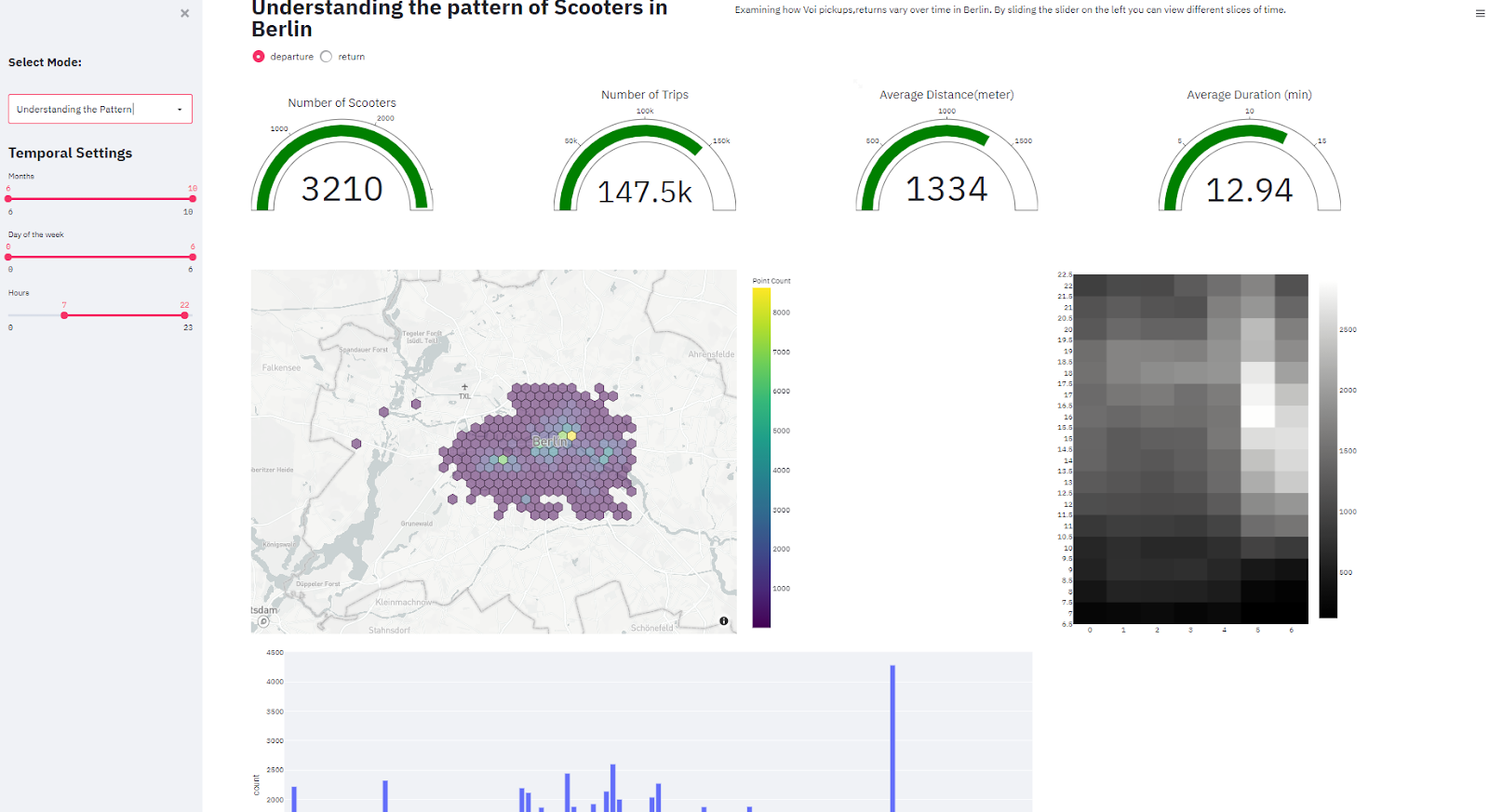
We proposed this dashboard in two webpages: understanding the trip pattern and idle duration/clustering. First page of this dashboard shows the trip pattern over Berlin.
First page shows the trip pattern over Berlin and includes the following elements:
Spatial variation of the trips.
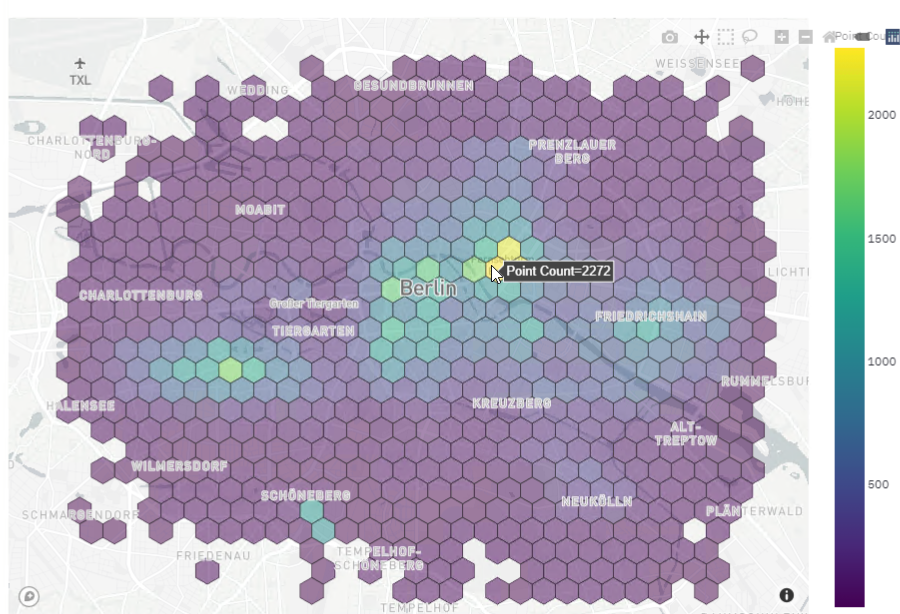
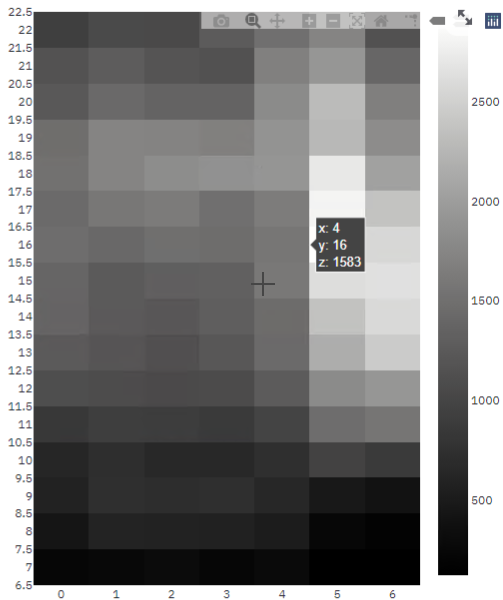
Heatmap that shows the hourly temporal variation of the trips in a week.
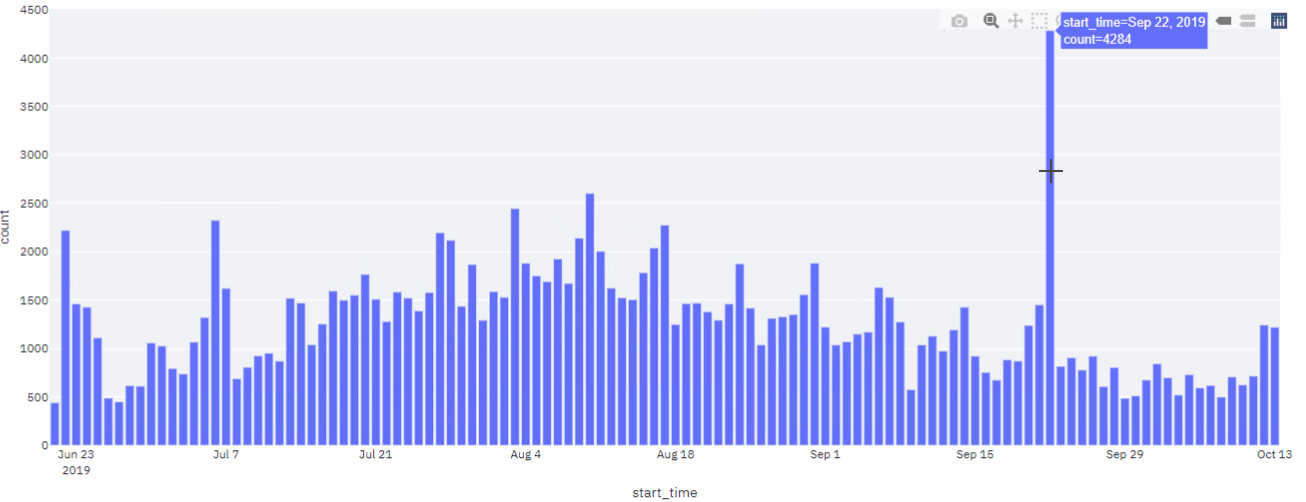
Bar chart that indicates the daily demand.
Main KPIs to measure ride sharing parameters
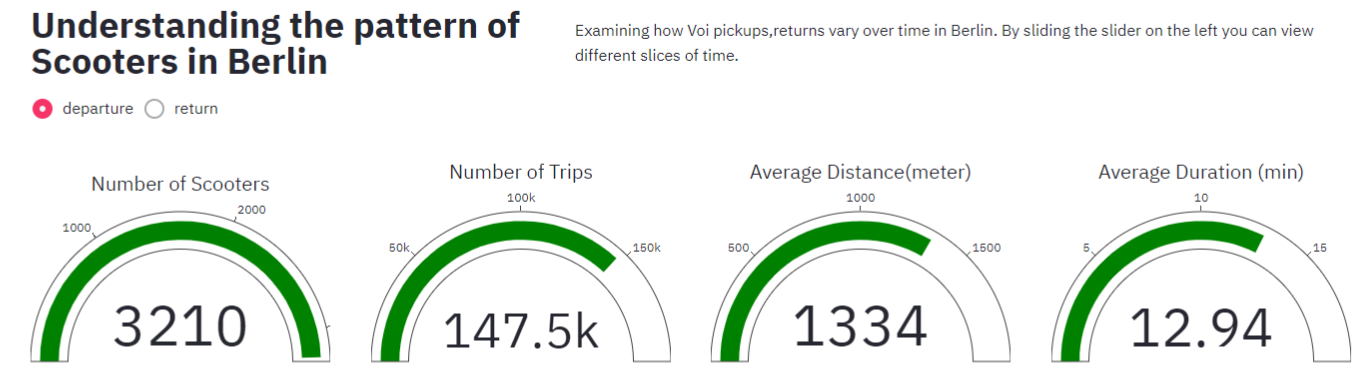
Left bar has parameters for temporal interactivity.

Idle Duration Indicator
Idle duration is an indicator that describes the time between two consecutive trips of the scooter. Besides other indicators such as riding duration, and pick-up demand of scooters, idle duration is a remarkable indicator that defines a scooter demand in an area. Throughout the study field, areas oversupplied and undersupplied by scooters can be detected easily. This indicator can be used for rebalancing problems between areas and battery problems of scooters. Theoretically, areas clustered with scooters having a short idle duration indicate high demand while scooters that have greater idle duration signify low demands. Therefore, the operation of rebalancing can be achieved by adjusting bicycles between areas. Besides, rebalancing problem of areas, this indicator can also help to solve the charging issue of scooters. The scooters with low idle duration normally need to be charged frequently.
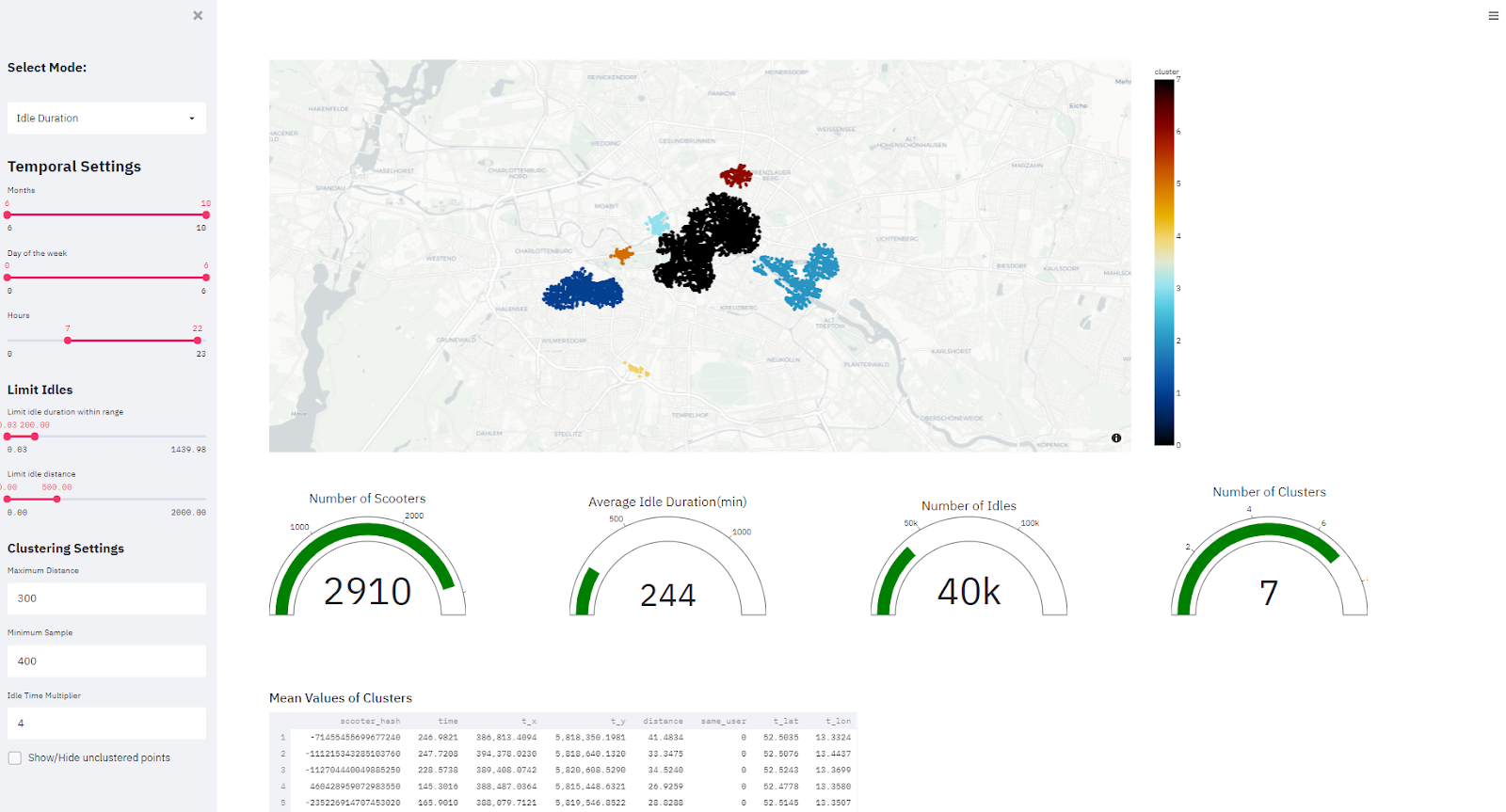
Interactive Dashboard for Idle Duration Indicator and Clustering
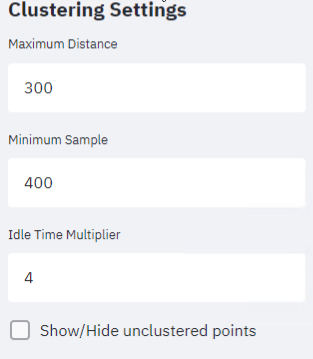
Second mode of this dashboard is to derive clusters of scooters based on three parameters: longitude, latitude, and idle duration. The 3D DBSCAN algorithm is utilized with the interactive layout meaning that decision makers can modify algorithm parameters to produce different clusters (Figure below).
Likewise, sliders for the temporal settings are also available in this mode in order to confine trips within the timeframe specified. Since, some scooter movements between two consecutive trips vary in a great degree (up to 32km) as well as idle duration of some scooters are steeply higher (up to 1440 min), idles can be enclosed by using sliders (figure below).

On the body of this page, the map is placed to illustrate clustered results (Figure below).
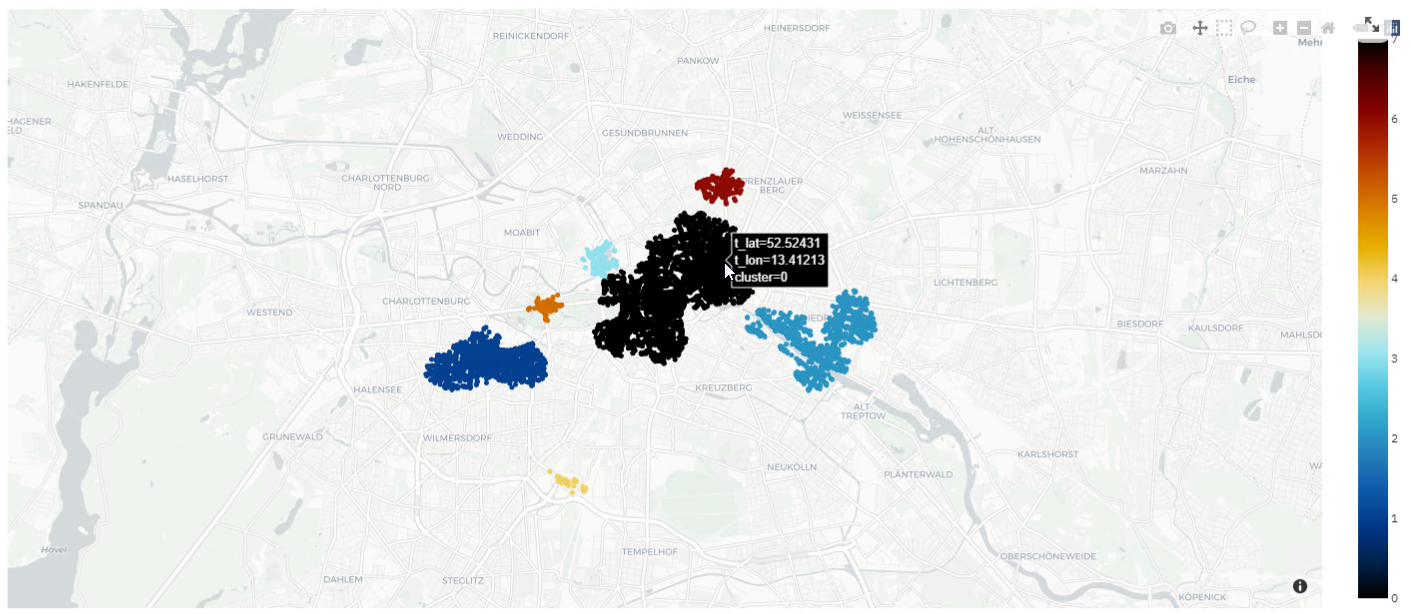
Bottom of the map, gauges are utilized to present some indicators of idle scooters (Figure below).

Data Preprocessing
Data Cleaning
Following the brief eyeballing on the dataset, a python script is created to clean anomalies and insignificant trips. This script named data_cleaning.py can be found in the main folder. Output data frames are saved under the data folder (appendix c).
Column names of the dataset are simplified.
Timestamp of the gps tracks is converted to the data type datetime64.
Decimal places of float numbers are simplified.
Outliers points out of the study area are removed (e.g. Potsdam).
Coordinates are projected and saved into the UTM33 projection system(epsg:32633).
Speeds and distances of trips are calculated.
Anomalies in the duration, distance and speed columns are ruled out (decisions are made based on univariate analysis).
Min, Max and list of the temporal information is calculated in order to be used for sliders in temporal settings.
Idle Duration Calculation
A python script is created to calculate idle duration between two consecutive trips. This script named trips_idle_duration.py can be found in the main folder. Output the dataframe idle_scooters.csv are saved under the data folder. The output dataframe is as follow:

Limitations
Precise boundary of the study area is unknown. It is undefined whether Point cloud in Potsdam is included in the study field of the operation or not.
Out datasets cannot be included in the analyses.
Discussion / Future Work
Other clustering algorithms can be added to compare results (K-means, Getis-Ord Gi*). Technically, Getis Ord Gi (hotspot/coldspot analysis) derives the areas with high values and low values so that utilization of scooters can be simplified into 2 clusters. Another utilization approach is to divide the study field into grids and calculate the mean idle duration of each grid to depict contrast. Indeed, Correctly tuned temporal settings lead to solving utilization problems more precisely.
Using 2D cluster algorithms for the location of pick-up demands can apply to geofencing applications. This indicator is in fact another approach for the utilization of a scooter that can be used for rebalancing problems so that the clustered areas are in need of scooter supplies.
However, further geospatial analysis is required to perform better utilizations. For instance, Point data should be aggregated into polygons and the number differences between pick-up and drop-off demand should be calculated. Subtracting Drop-off demand from the Pick-up demand in each polygon is an indicator of being oversupplied (negative values) or undersupplied (positive values). However, one should keep in mind that the actual pick-up demand is not the starting point of the trips, in fact actual demand is the location where the user starts the app to check the nearest scooter.
Although the temporal and spatial pattern of the trips is not an indicator of the operation unit, the first mode of this dashboard is created to understand spatio-temporal pattern. Scooter demand in a week can be divided to weekdays and the weekend, since the intra-pattern in those groups is relatively similar. Additionally, the pattern in a day also varies. Therefore, the time unit for the operations can be formed on those deductions. Also, anomalies can be easily detected and further actions like normalizing those anomalies can be performed (huge demand on September 22 2019).
Locations of warehouses, charging stations and maintenance facilities is also another consideration that needs to be optimized based on the fleet movement over study area. For example, charging stations can be located where the scooters with high utilization efficiency are clustered. Optimal location of those facilities is a facility location problem that can be solved with maximal coverage or p-median approach.
Furthermore, optimal fleet management along with the optimal location of facilities will lead to less emission of greenhouse gasses and human-resources. Dashboards for the optimal management can be created with optimization algorithms, however, distance calculations should be derived by the street networks not Euclidean distances (requires additional dataset).
Conclusion
Understanding the spatio-temporal pattern of the scooter flow and its explanatory factors can be used to improve utilization of scooters. The main indicator of this dashboard, idle duration of scooters, is selected due to its effective indication on supply and demand in a study area.
In this application, a streamlit python library is used to create the layout of the dashboard, while plotly is used for visualisation purposes. Python is used due to the compatibility with machine learning and geostatistical tools. Gauges are used to display generic information (mean and total number of some attributes) of the selected areas and timeframes. Type of chart used in this dashboard: hexagon and points maps, temporal heatmap, bar charts. Additionally, tables including mean values of clusters can be viewed on the bottom page of the second mode. Sidebar of this dashboard includes temporal, idle and clustering settings.
References
Electric fence planning for dockless bike-sharing services, Zhang et al., 2019
Getis, Arthur, and J. K. Ord. “The Analysis of Spatial Association by Use of Distance Statistics.” Geographical Analysis 24, no. 3. 1992.
Appendices
Appendix A: Libraries/functions used:
import pandas as pd
import streamlit as st #dashboard
import plotly.express as px #visualization
import plotly.graph_objects as go #visualization
import plotly.figure_factory as ff #visualization
from sklearn.cluster import DBSCAN #clusteringAppendix B: Activate environment and the dashboard
Appendix C: Main dataframe
Appendix D: Layout of the Idle Duration Mode
Appendix E: Spatio-Temporal Pattern
We share articles about GIS applications, remote sensing, and programming. Check our Free tutorials on desktop GIS and coding! don’t hesitate to contact us.